본 포스팅은 "알면 쉬운 도커 쿠버네티스" 책을 정리한 글입니다.
구매링크 : http://www.yes24.com/Product/Goods/91618364
해야할 일은 이렇다.
- nginx 이미지 다운로드.
- nginx index.html 변경
- nginx 이미지 기반에 2에서 변경한 index.html 커밋해서 새로운 이미지 만들기.
- 컨테이너화 해보기
nginx 이미지 다운로드
terminal에서 다음과 같은 명령어를 입력한다.docker pull nginx
그 다음 docker images 명령어로 nginx 이미지가 제대로 다운로드 됐는 지 확인해보자.

nginx 이미지로 컨테이너 만들기
terminal 에서 다음과 같은 명령어를 입력한다.docker run --name nginx -p 8080:80 -d nginx
이와 같은 명령어를 입력하면, 컨테이너 외부 8080 포트에 컨테이너 내부(nginx이미지 기반) 80포트와 매핑 시켜준다.docker ps 명령어로 실행중인지 확인해보고, localhost:8080으로 접근해보자

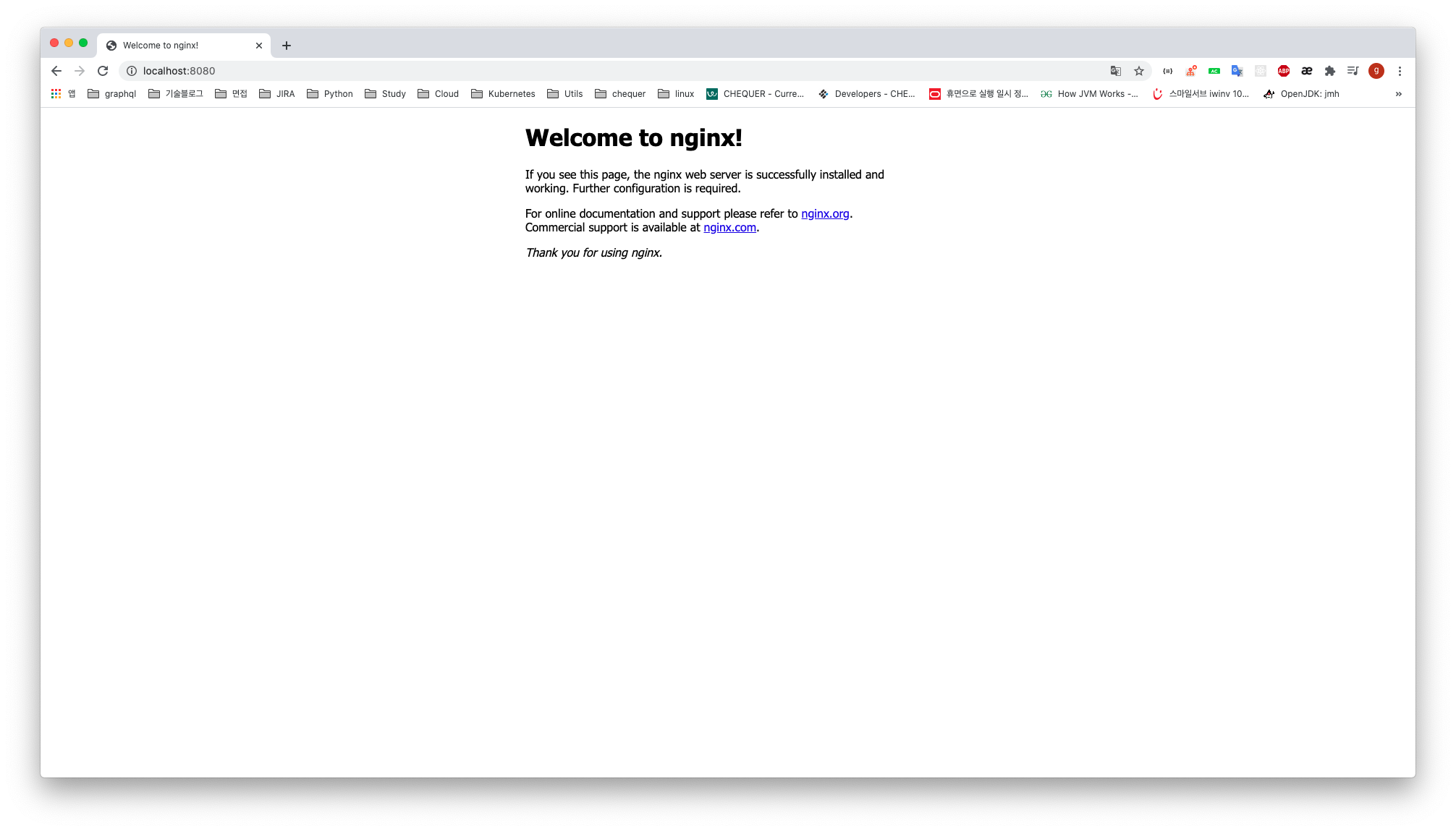
nginx의 index.html 파일 변경.
현재 localhost:8080 으로 접속해서 보이는 페이지가 nginx 의 index.html 이다.
위치를 찾아보자.
먼저 컨테이너 내부로 들어가보자.docker exec -it nginx /bin/bash
내부로 들어왔으면 다음과 같은 명령어로 index.html 을 찾아보자find / -name index.html 2>/dev/null
이 명령어로 index.html의 위치를 찾을 수 있다 현재 위치는 /usr/share/nginx/html/index.html이다.
이 파일을 호스트로 복사하자. 먼저 exit명령어로 컨테이너 내부에서 빠져나온 뒤 다음과 같은 명령어를 실행하자.docker cp nginx:/usr/share/nginx/html/index.html index.html
제대로 복사됐는지 ls -al 명령어로 확인해보자.
그 다음으로는 복사된 index.html 을 수정하자.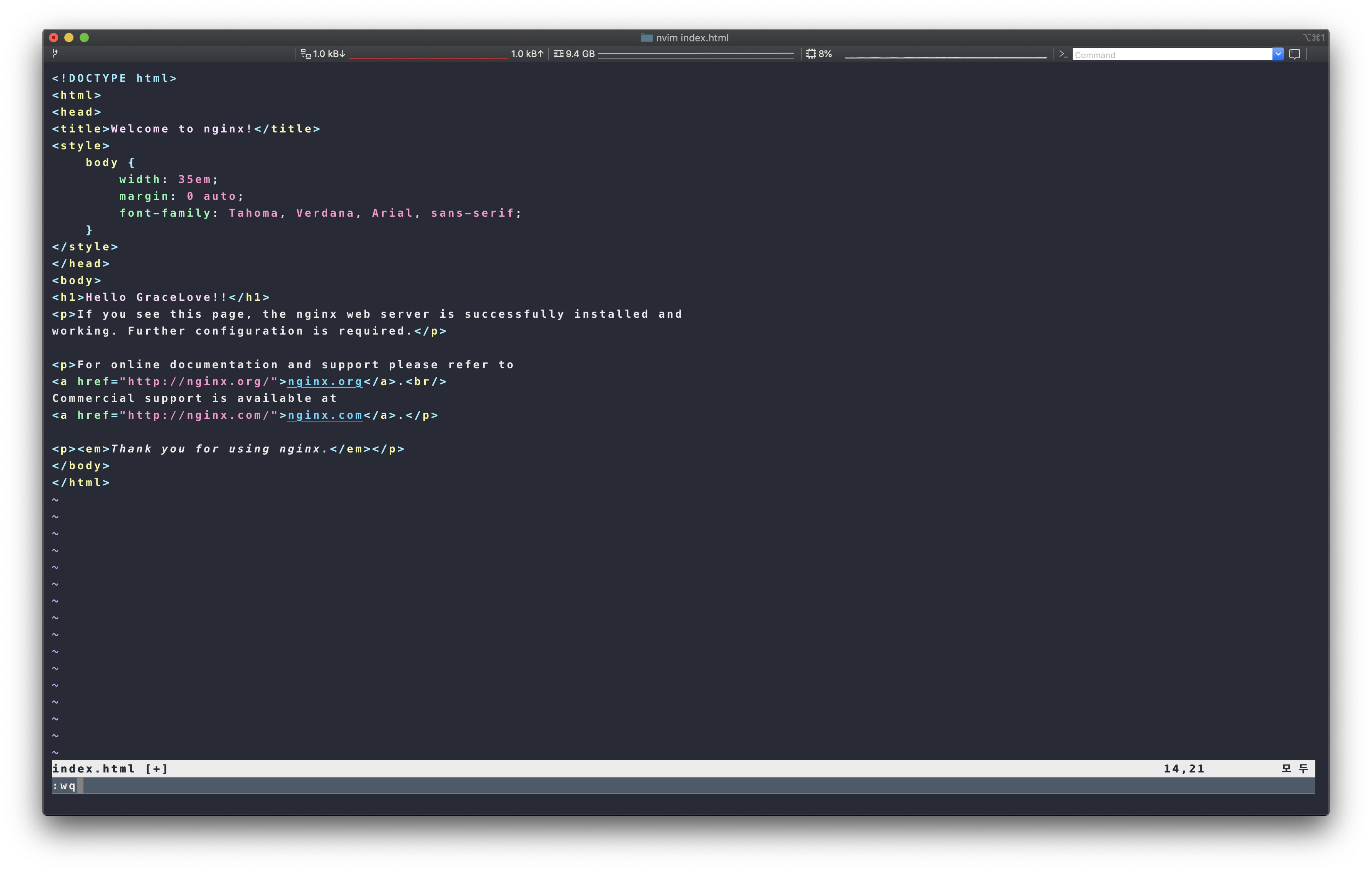
수정한 index.html 파일 nginx 이미지 내부에 집어넣기.
아까와 비슷하다 복사 명령어로 nginx 내부에 있는 index.html 파일을 우리가 변경한 index.html 파일로 덮어써버리자.
주의할 점은 이미지가 현재 컨테이너화 되어 있어야 한다. 실행중인 상태든, 정지된 상태든 괜찮다. 일단 컨테이너화 되어있어야 한다.docker ps -a로 확인할 수 있다.
docker cp index.html nginx:/usr/share/nginx/html/index.html
현재 이름이 nginx 인 컨테이너의 위치에 index.html을 복사하는 명령어다.localhost:8080으로 접근했을 때 띄워져있던 페이지를 새로고침해보자. 위에서 수정한 것처럼 title이 Hello GraceLove 로 바뀌었다.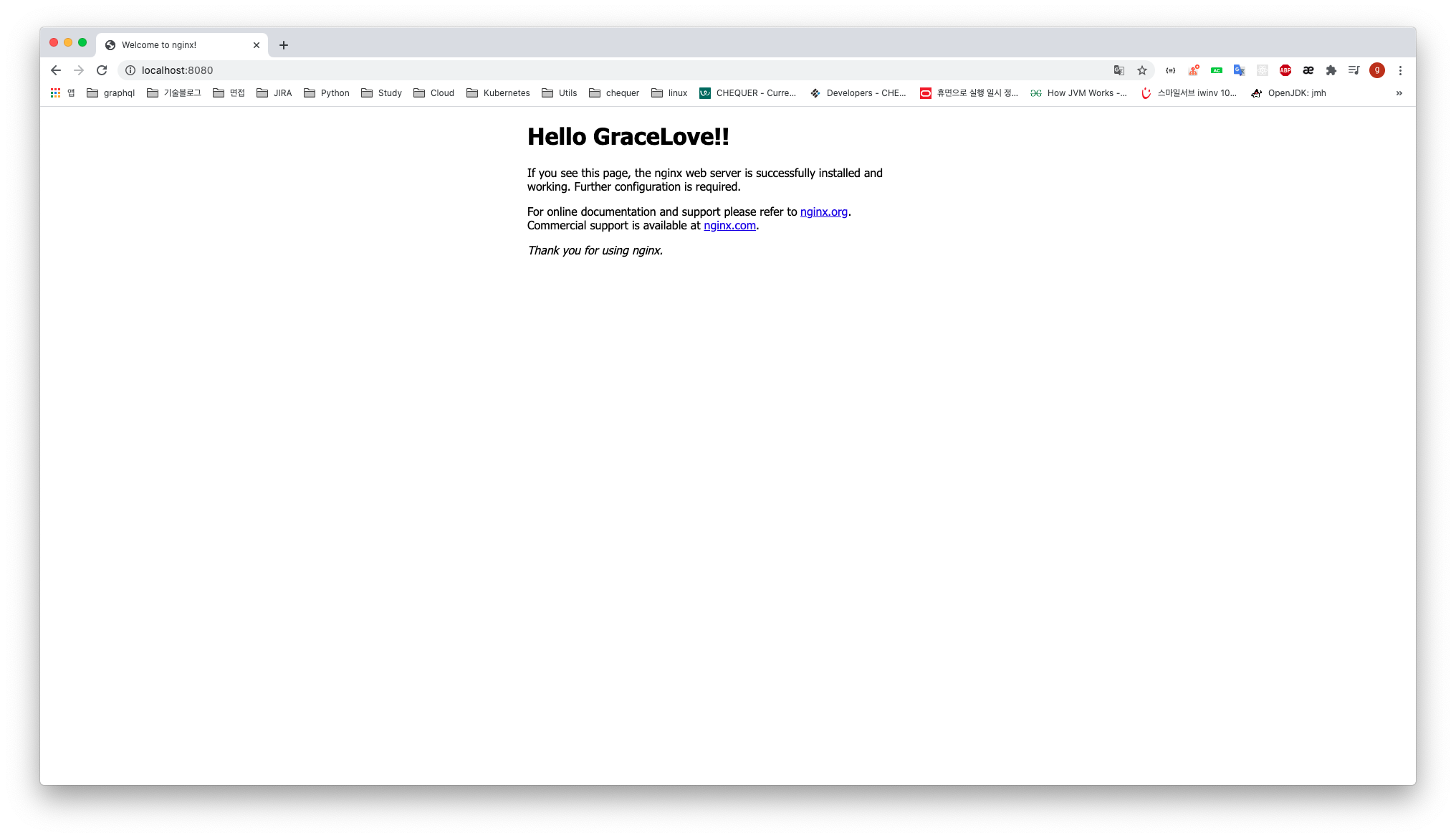
수정한 컨테이너를 이미지화 시키기.
하지만 도커 이미지는 불변이다. 우리가 컨테이너를 지지고 볶고 하더라도, 이미지는 바뀌지 않는다.
실험해보고싶은 분들은 docker stop nginx , docker rm nginx 명령어로 컨테이너를 지우고 다시 docker run...을 해보자.
방법 1.
이제 우리가 변경한 컨테이너를 기반으로 도커 이미지를 만들어보자.
다음과 같은 명령어를 입력한다.docker commit nginx mynginx
nginx라는 이름을 가진 컨테이너를 mynginx라는 이름을 가진 이미지로 만드는 것이다.
다음과 같은 명령어를 입력해서 image 가 됐는 지 살펴보자.docker images | grep mynginx
방법2.
Dockerfile을 이용하자.
다음과 같이 만들자.vi Dockerfile (vim의 사용법을 모르겠다면, 일반적인 텍스트 에디터를 사용해도 좋다.)
아래와 같은 내용을 채워넣는다.
FROM nginx
COPY index.html /usr/share/nginx/html/이제 빌드를 해서 이미지를 만든다.docker build -t mynginx2 .
다음과 같은 명령어를 입력해서 image 가 됐는 지 살펴보자.docker images | grep mynginx2
우리가 만든 이미지와 기존 nginx 이미지를 컨테이너화 시켜서 비교해보기.
현재 실행 중인 모든 컨테이너를 지우자.docker stop [container id] -> docker rm [container id]
이제 docker ps -a 을 하면 아무것도 나타나지 않아야 한다.
깨끗한 상태에서 우리가 만든 이미지와, 기존의 nginx 이미지를 컨테이너화 시켜서 비교해보자.docker run --name mynginx -p 8080:80 -d mynginx2docker run --name originnginx -p 9090:80 -d nginx
그 다음 각각 localhost:8080 과 localhost:9090 으로 접속해보자.
우리가 만든 이미지는 컨테이너화 할 때 port 8080으로 연결시켰고, 기존의 nginx 이미지는 9090에 연결시켰다.
서로 다른 index 페이지를 보여주는 것을 볼 수 있다.
